eBooks Context Browser Info
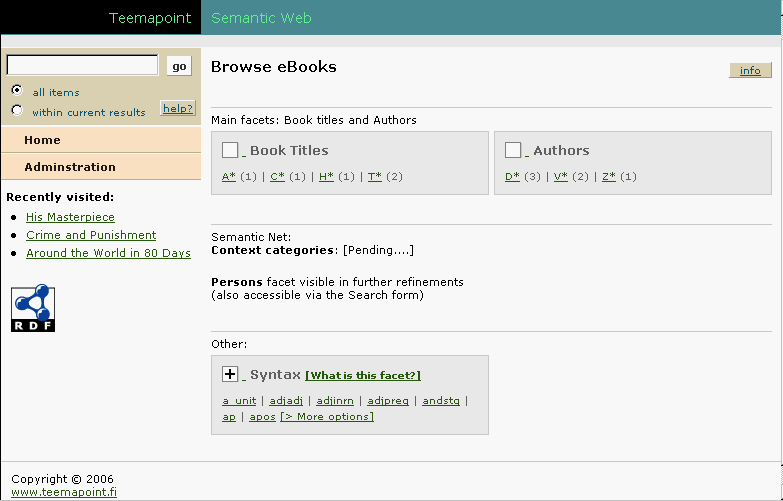
The data objects are organized according to the characteristics or facets which
are shown in the grey boxes. The numbers in the brackets show how many results are in that facet.
To start browsing pick an option from one of the facets.
Syntax and Person facets have been automatically extracted from books
listed in the Book Titles facet.
Usually a couple of first chapters in each book have been processed.
Syntax facet might have value for people interested in linguistic patterns.
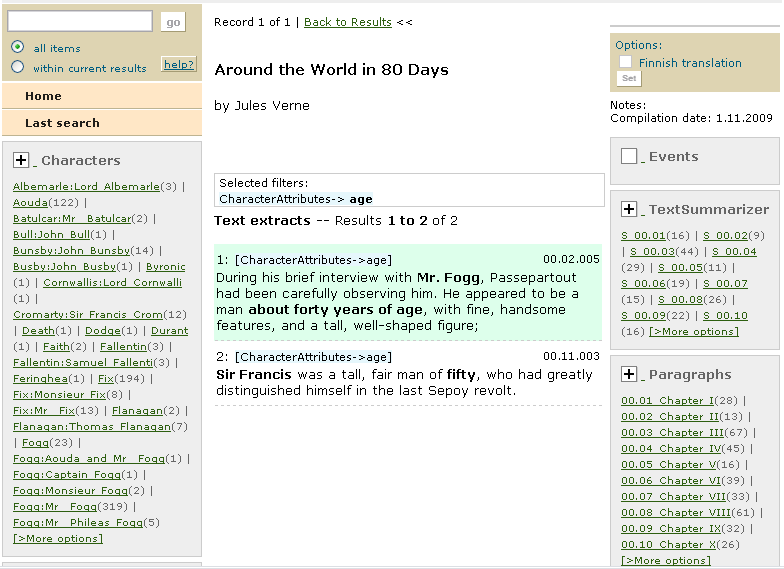
Persons (or characters) facet contains more relevant information for the audience.
Similar facets and their relationships will be added in the future
(Context categories). Currently some character attributes have been extracted and tagged
by the semantic tagger which uses tools such a
natural language parser.
The results of the parser are used as a basis for methods including word sense disambiguation
and reference resolution.
The database is structured using semantic web data formats.
To be real semantic web data, this data should be available for other
applications in the net and/or this application should harvest
related contents from other sites.
For now, this acts as a normal centralized database.
Core functions of the interface to the semantic web data are based on the
Semantic Web Environmental Directory portal demonstrator
developed by Hewlett Packard as part of the SWAD-Europe project .
|